File format requirements
The standard file format for the TMA-Combiner is the PCL format.
The PCL format is the Pre CLuster format as described in the TMA-Deconvoluter
walkthrough. It is one of the two output formats of the
TMA-Deconvoluter. Since the TMA-Combiner is designed to work with
the TMA-Deconvoluter, this should not present a problem to most
users.
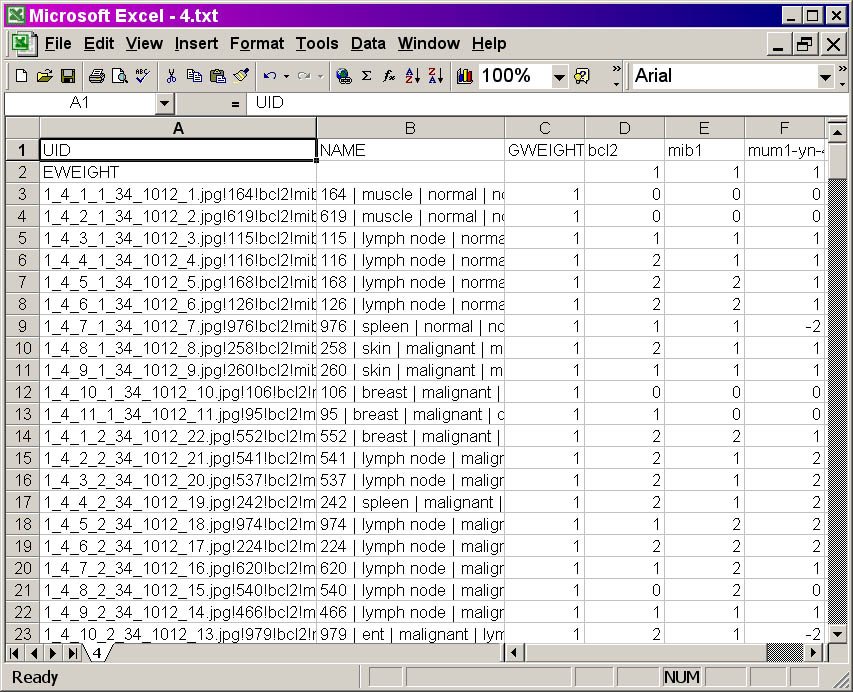
Below is an example of the PCL format:
PCL File layout -- screenshot

Click on the image for a larger view of the picture.
- Column A: UID (for Unique IDentifier; required). If you use
Stainfinder, this column contains the image filename and antibody
stains that are passed into the Stainfinder program. The way this is
done can be found here under
the Stainfinder walkthrough.
- Column B: NAME (required). This is the most important column in the
file, since the TMA-Combiner uses this as the basis for identifying
replicates, for subsequent "compression". Each cell contains a case
number followed by various descriptors, all of them each separated by
a "pipe" ("|") delimiter. For example:
1208 | breast | malignant | carcinoma | ductal | invasive
Your NAME column must contain the case
number as the very first item (1208 in this example), and your NAME column must use the
"pipe" ("|") character as the delimiter. Again, this is the standard
format used in the TMA-Deconvoluter output files, so this should not
pose any problems for most users.
- Column C: GWEIGHT (optional but highly recommended). This
is the "GWEIGHT" column used by the Cluster program for providing the
option of weighting cases differently (see TMA website and Cluster
manual for details). The PCL file format incorporates this column by
default; if it is absent in the input file, it will be inserted by the
TMA-Combiner.
- Column D, etc.: Antibodies. Row 1 contains the name of
the target protein for the antibody stain. If different TMAs contain
the same antibody, and/or if a given TMA contains replicates or
multiple score sets (e.g. by different pathologists), the name of the
target protein should be separated with an underscore ("_") from the
initials of the scorer or other unique identifying information. This
is very important because TMA-Combiner will use that as the basis
for determining what columns are to be combined, and any names that
are not identical will be treated as different entities that will not
be combined. For example:
| Column |
Before |
After |
| D |
bcl2 |
bcl2 |
| E |
mib1 |
mib1 |
| F |
er_mv-10-00 |
(2)er |
| G |
er_lt-03-01 |
-- |
| H |
ER |
ER |
| I |
mib2_yv-10_03 |
mib2 |
Note that Column H will NOT be combined with Columns F and G,
because the name matching is case sensitive. Furthermore, any
annotations after the leftmost ("_") will be truncated (such as
for Column I), even if the column is not combined with any other columns in the final dataset.
- Row 2: EWEIGHT (optional but highly recommended). This
is the "EWEIGHT" row used by the Cluster program for providing the
option of weighting antibodies differently (see TMA website and Cluster
manual for details). The PCL file format incorporates this row by
default; if it is absent in the input file, it will be inserted by the
TMA-Combiner.
Note: the TMA-Combiner will output files in PCL format,
regardless of the format of the input files.
Other formats
While the PCL file format is the native format of the
TMA-Combiner, it will recognize two other formats, for ease of
convenience to the user. Note: if problems arise, the user is
requested to use the TMA-Deconvoluter to output into the PCL
format.
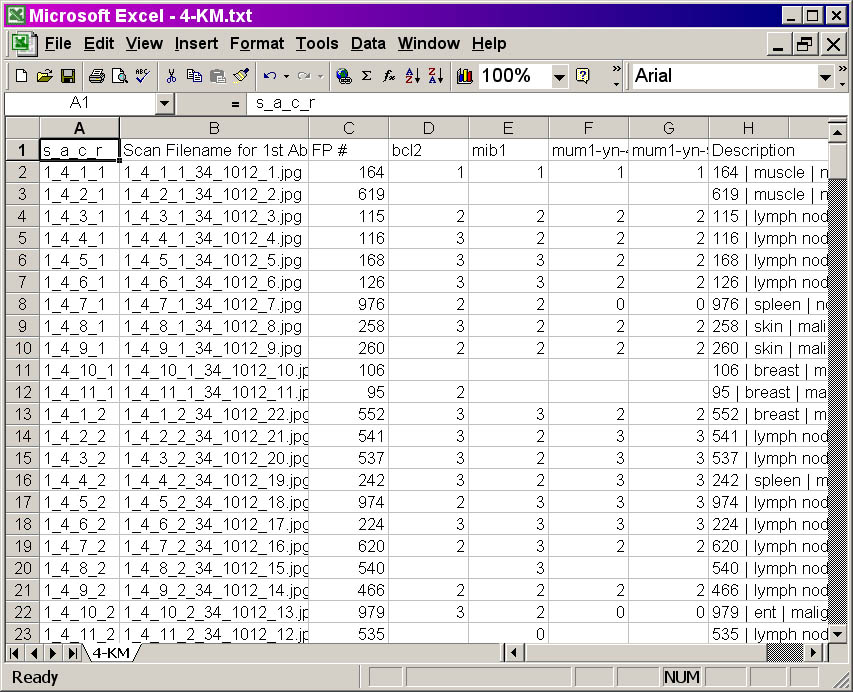
- The K-M format. A detailed description of this format is present
here. An example of this format
is shown below.
K-M File layout -- screenshot

Click on the image for a larger view of the picture.
- A simple text tab-delimited format. This would be equivalent to
the PCL format, except that the UID and GWEIGHT columns and the
EWEIGHT row are missing.
|